Split Application Backend Persistence
Context and Motivation
An application implements a domain model with its entities, relationships, services, and so on. Parts or all of the data are stored in a database or other data store.
As an application architect, I want to move persistence management (i.e., storage and efficient retrieval of business objects and other data) to a separate physical node and/or tier so that the resulting design-time and runtime properties meet the project goals, functional and non-functional requirements, and constraints in an adequate, balanced way.
Note that moving the permanent data storage to a separate node and/or tier has a significant impact on the data access logic. A remote interface has to be introduced, subject to the fallacies of distributed computing.
Stakeholder Concerns
- #data-freshness
- Local data is less likely to outdate than remote data.
- #data-ownership-and-placement
- Distributed data, which may originate from different sources, with different locations and owners, is more difficult to validate, integrate, and use than homogeneous local data.
- #flexibility
- Data models evolve just like code and the domain models driving design and development; both flexibility and rigor are desired when it comes to changing these models. A large body of work on this tradeoff exists in database and data management research.
- #performance
- Queries and other SQL operations should perform in such a way that the end-to-end performance goals of the system can be met.
- #security
- Moving persistence to a separate tier or host introduces new security considerations. Authentication, authorization, encryption in transit, and network segmentation become essential to protect data. Reducing the attack surface and isolating critical data are common goals.
See Split Application Backend Logic for additional concerns. The forces in “Client/Server Architectures for Business Information Systems – A Pattern Language” [Renzel and Keller 1997] also qualify as such concerns.
Initial Position Sketch
This refactoring targets the data access/persistence layer of logically layered applications (logical layering is a prerequisite for this refactoring). An illustration of such a logically layered monolithic backend is shown in Figure 1. These layers are explained further in the Initial Position Sketch of Distribute Application Frontend, and detailed descriptions can be found in “Patterns of Enterprise Application Architecture” [Fowler 2002].
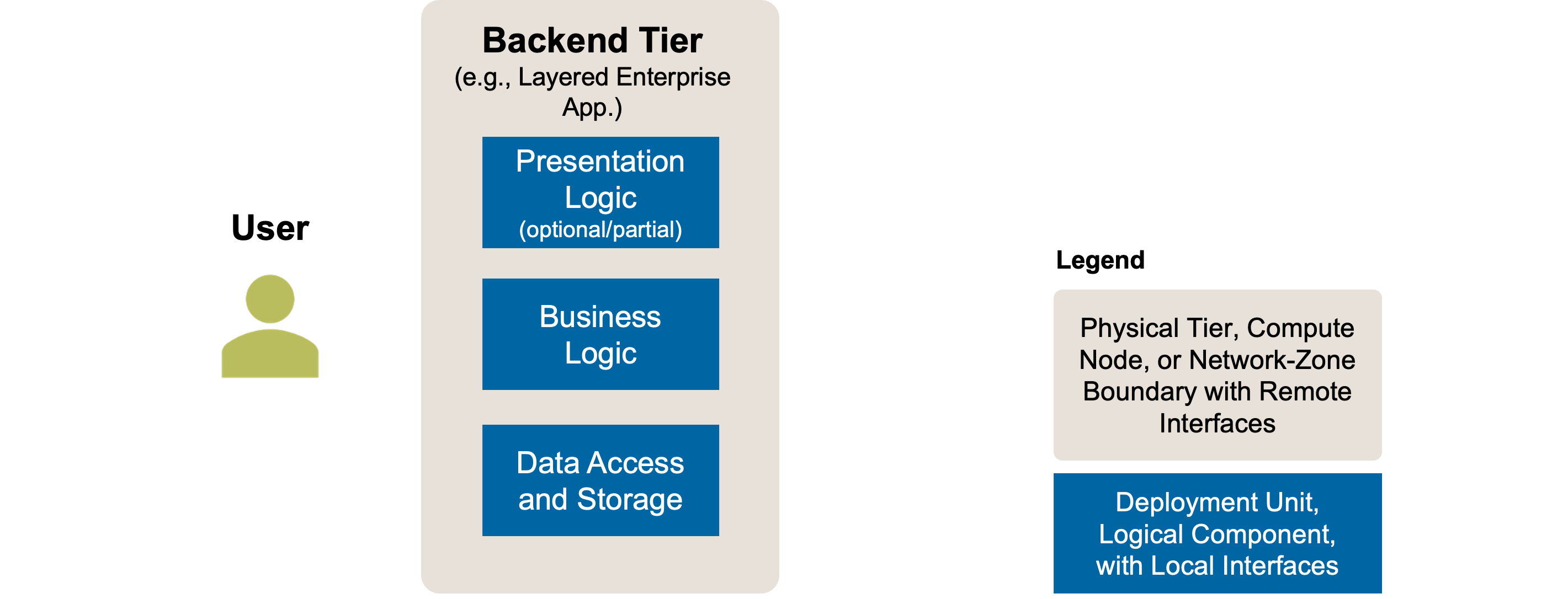
Figure 1: Split Application Backend Persistence: Initial Position Sketch. A logically layered monolithic application backend (same initial position as in Split Application Backend). Note that, as in other figures, a client tier hosting parts or all of the application frontend (presentation logic) might exist but is not shown.
Smells
- DevOps-DBA goal conflicts
- Database Administrators (DBAs) and DevOps personnel prioritize desired qualities differently (for instance, availability vs. performance or deployment speed). Addressing their concerns on a single host, with no remote database in place, causes conflicts.
- Conflicting data ownership
- In monoliths (i.e., monolithic systems or monolithic backend), a single shared database might be accessed by multiple teams or modules without clear ownership boundaries. Such ungoverned or uncontrolled data access leads to coordination overhead, might cause accidental data overwrites, and makes it difficult to evolve the schema or enforcing validation consistently.
- Insufficient security isolation
- When no remote database is in place, the system runs application logic and stores data on the same machine or in the same network zone. A single vulnerability or misconfiguration can expose both layers at once. There is no clear boundary to limit the impact of security incidents.
- Poor database performance
- Queries and other SQL operations might be slow to respond when the workload of the host machine on which the database management system runs also contains tasks that are not related to data management. More scheduling and resource sharing is required, which has to be coordinated.
See Split Application Backend Logic for additional smells. The forces in “Client/Server Architectures for Business Information Systems – A Pattern Language” [Renzel and Keller 1997] also identify reasons to apply this refactoring.
Instructions
Two options for splitting the application backend persistence exist, which differ in their target architecture [Renzel and Keller 1997]:
A. Relocate Database. Switch from local to remote database. B. Distribute Database. Split and partition a single database, possibly introducing redundancy. Deploy the parts to different nodes.
Target Solution Sketch (Evolution Outline)
The two options apply two of the client-server-cuts, also known as “distribution patterns”, from Renzel and Keller [1997], Remote Database and Distributed Database. They can be combined with each other and with the other three client-server cuts, two of which dealing with application frontend decomposition (Distributed Presentation, and Remote User Interface) and one dealing with backend logic (Distributed Application Kernel).
Option/Variant A: Relocate Database
Option A, switch from local to remote database, is sketched in Figure 2.
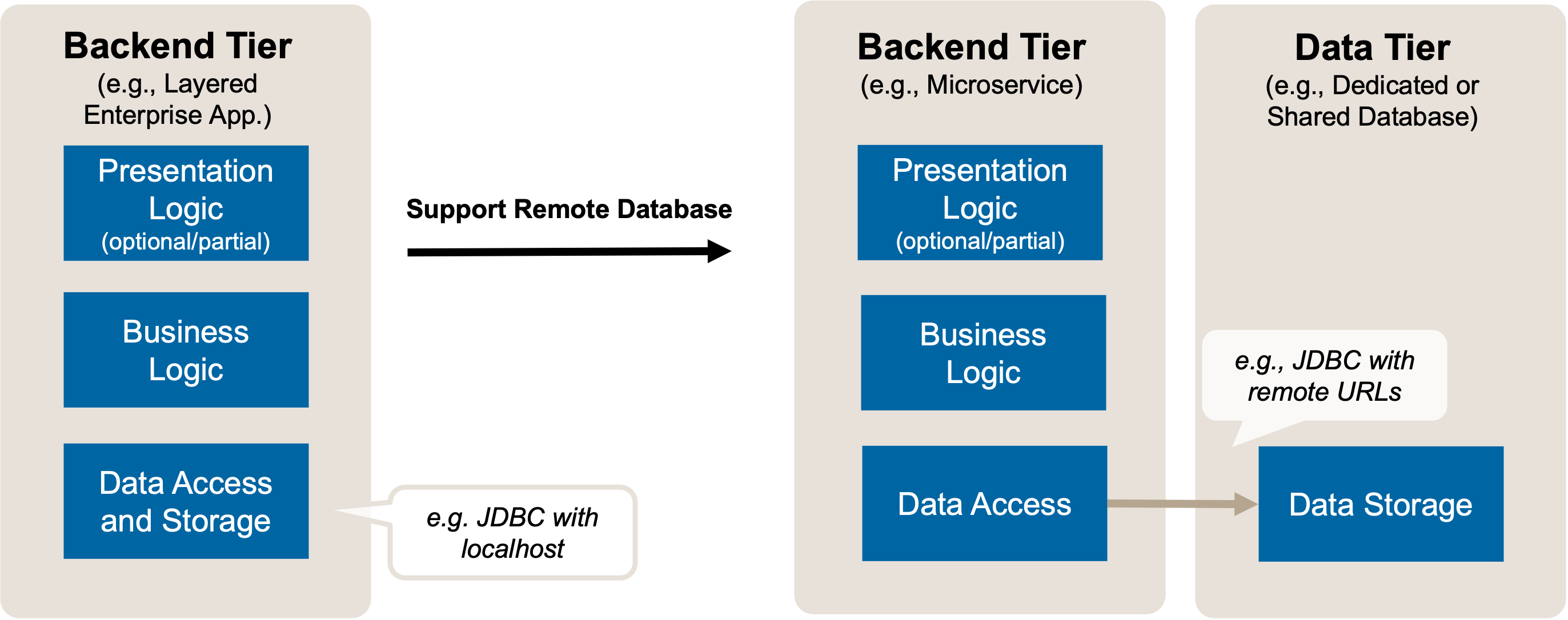
Figure 2: Split Application Backend Persistence: Target Solution Sketch. From Local Database to Remote Database. A client tier hosting parts or all of the application frontend (presentation logic) might exist but is not shown.
A remote interface between the data access logic and the database is introduced. For instance, a local JDBC connection, indicated by a URL starting with https://localhost is replaced with a remote JDBC connection in a Java Spring Boot application connecting to a relational, SQL-based database. Changing a server address in a configuration file might come across as trivial and not justifying an IRC entry, an architectural refactoring. However, this change has major consequences for runtime qualities as an additional deployment unit and, possibly, compute node or even network zone have to be managed; response times are expected to change. Proper testing and monitoring is required. Applying the refactoring is one small step for a developer, a giant leap for DevOps.
Option/Variant B: Distribute Database
Option B, distribute database, is sketched in Figure 3.
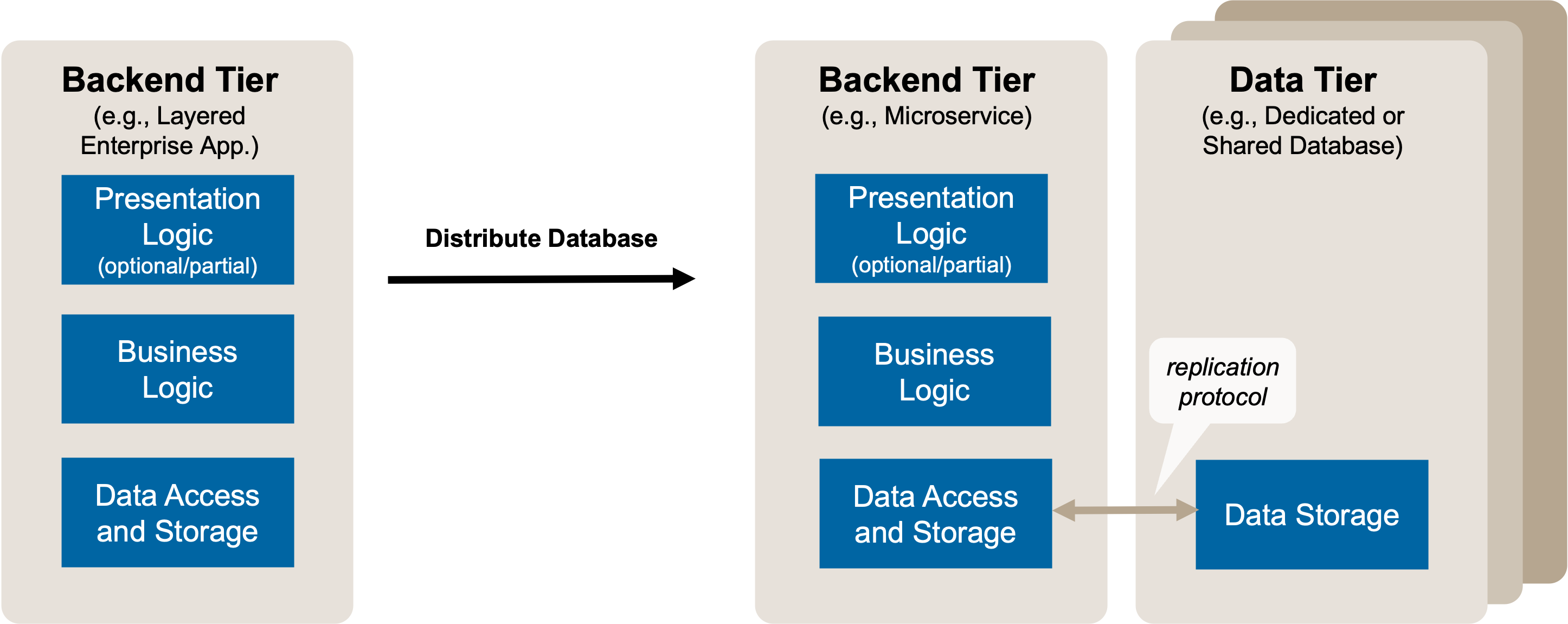
Figure 3: Split Application Backend Persistence: Target Solution Sketch. From Single Database to Distributed Databases. Again, a client tier hosting parts or all of the application frontend (presentation logic) might exist but is not shown.
Two (or more) physical database instances exist, supporting scalability and reliability through failover. They communicate via replication protocols, often proprietary, or via event sourcing triggered by stored procedures managed by the database instances. The instances might overlap in their content from full replication, where copies of the database are distributed, to sharding (also known as partitioning), where the data is sliced according to some criteria (for example, by customer) and these slices are then distributed. Both approaches can also be combined: the data is sharded first and each shard is then also replicated. The choice between these options depends on the specific needs for scalability and reliability, but also available infrastructure and economic factors. Note that the databases can be distributed to different remote regions; this is not shown in Figure 3. See “Designing Data-Intensive Applications” [Kleppmann 2017] for a deeper discussion on how to distribute databases.
Example(s)
See Split Application Backend Logic.
Hints and Pitfalls to Avoid
Splitting an application backend is a “big” architectural decision, which requires careful evaluation and justification [Zimmermann and Stocker 2021]:
- Balance ACID and BASE properties when it comes to data consistency management; sticking to the metaphor from chemistry, find a suited “pH value” for the backend design solution.
- Make sure that the expenses caused by remoting (serialization and deserialization of data, transport over a network) pay off by the increased amount of parallel processing (e.g., query plan optimization by RDBMS on dedicated hardware) and additional opportunities of hardware and software sizing and tuning on the new remote database tier.
- When using remote or replicated databases, be aware of the risk of stale data. If strong consistency cannot be guaranteed, design the user experience and validation logic accordingly.
- Avoid direct dependencies on shared database schemas across modules or services. Introduce clear API or access boundaries to reduce the impact of schema changes and enable more independent evolution.
- Distribution of persistence introduces new security risks. Enforce access control, authentication, and encryption for sensitive data. Use firewalls and network segmentation to protect communication paths and reduce the risk of misconfiguration. See the OWASP Foundation website or practical resources and guidance on addressing common application and data security risks.
- Separate personal or confidential data from public or low-risk data. Apply appropriate access controls and encryption, and ensure clear responsibility for securing each data category.
Related Content
Other architectural refactorings in this catalog include Segregate Commands from Queries, Distribute Application Frontend, and Split Application Backend Logic. Note that these refactorings can be combined. It is possible to apply them progressively (multiple times).
See Split Application Backend Logic for more information and related work.
References
Fowler, Martin. 2002. Patterns of Enterprise Application Architecture. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc.
Kleppmann, M. 2017. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. O’Reilly Media.
Renzel, Klaus, and Wolfgang Keller. 1997. “Client/Server Architectures for Business Information Systems – a Pattern Language.” In Proceedings of the Conference on Pattern Languages of Programs. PLoP ’97.
Zimmermann, Olaf, and Mirko Stocker. 2021. Design Practice Reference - Guides and Templates to Craft Quality Software in Style. LeanPub. https://leanpub.com/dpr.