Introduce Pagination
also known as: Paginate Responses, Slice Response Message
Context and Motivation
An API operation returns a large sequence of Data Elements. For example, such a sequence may enumerate posts in a social media site or list products in an e-commerce shop. The API clients are interested in all Data Elements in the sequence but have reported that processing a large amount of data at once is challenging for them.
As the API provider, I want to return data sets in manageable chunks so that clients are not overwhelmed by a huge amount of data arriving at once.
Stakeholder Concerns
- #data-access-characteristics
- In principle, the client wants to access all data elements, but not all have to be received at once or every time. For example, older posts to a social media site might be less relevant than recent ones and can be retrieved separately.
- #performance, #resource-utilization
- Transferring all Data Elements at once can lead to huge response messages that burden receiving clients and the underlying infrastructure (i.e., network and application frameworks as well as databases) with a high workload. For instance, single-page applications that receive several megabytes of JSON might freeze until all contained JSON objects have been decoded.
Initial Position Sketch
The API provider currently returns an extensive sequence of Data Elements in the response messages of the operation. Figure 1 shows this initial position sketch.
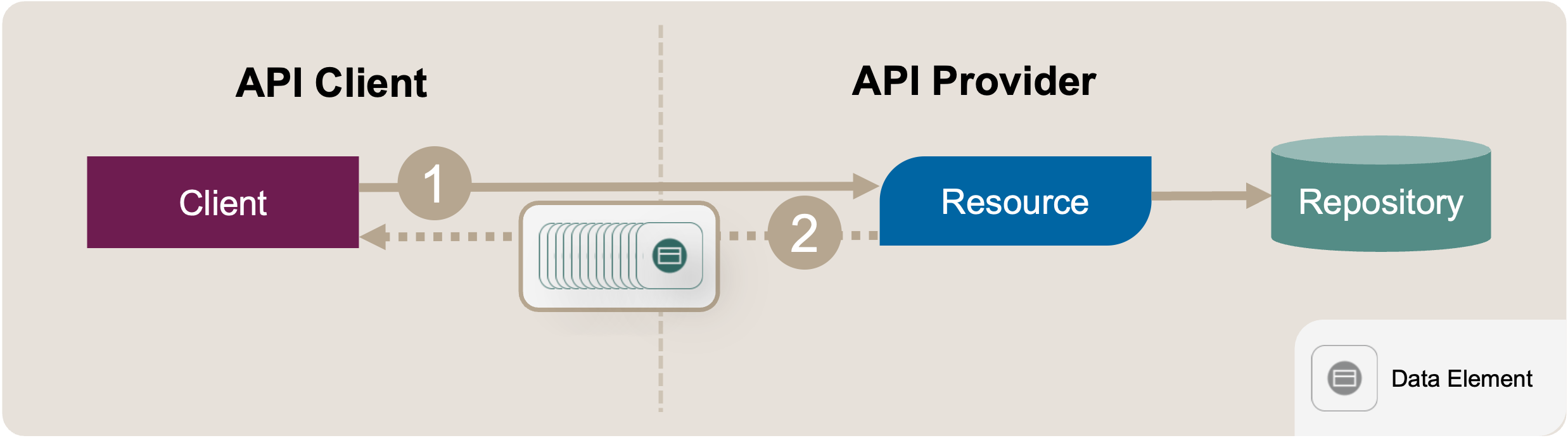
Figure 1: Introduce Pagination: Initial Position Sketch. The client’s request (1) is met by a large sequence of data elements (2).
This refactoring targets an API Retrieval Operation and its request and response messages.
Design Smells
- High latency/poor response time
- Responses take a long time to arrive at the client because a lot of data has to be assembled and transmitted. This might be evident in a provider-side log file analysis or client-side performance metrics.
- Overfetching
- A client may not need all data (at once or at all) and truncate an overly large dataset. Since this truncation happens on the client side, data was unnecessarily processed and transmitted.
- Spike load
- Regular requests for large amounts of data cause Periodic Workload [Fehling et al. 2014] for CPU and memory, for instance, when a large JSON object has to be constructed (on the provider side) and read (on the client side). For example, the “Time-Bound Report” variant of a Retrieval Operation might lead to relatively large responses, depending on the time interval size chosen.
Instructions
Decide on a variant of Pagination that best fits your API: Page-Based, Offset-Based, Cursor-Based, or Time-Based Pagination. Clients request the data differently in these variants; see the Pagination pattern description [Zimmermann et al. 2022] for details on the variants and their pros and cons.
- All variants involve certain metadata, so if the current response message directly returns the underlying domain model elements, possibly contained in a list, wrap the structure in a Data Transfer Object (DTO) first by applying the Introduce Data Transfer Object refactoring.
- Add additional response attributes to the DTO to hold the metadata required for Pagination (for instance, page size, page number, and the total number of pages for the Page-Based pattern variant).
- Adjust the expected parameters in the request message to give the client control over the number of results returned. Provide default values so that existing clients will continue to work.
- Enhance the unit and integration tests to include and check for these additional attributes. Test with different chunk sizes. Include complete versus partial retrievals and changes to data while being paginated to the test suite.
- Update API Description, sample code, tutorials, etc., with information about the Pagination options (for instance, variant, metadata syntax, semantics, and session management concerns).
- Increase the version number as suggested under Semantic Versioning. The refactoring typically results in a major update, but a minor update might be sufficient if the API provider implements the change in a backward-compatible way.
When already following the API best practice of consistently returning an object as a top-level data structure, it is straightforward to implement Pagination in a backward-compatible manner, returning all results as a single page if no control metadata appears in incoming requests. While this approach is backward-compatible, it does not remove any of the above smells.
Target Solution Sketch (Evolution Outline)
After the refactoring, the client indicates the desired amount and position in the sequence of data in their request messages (depending on the Pagination variant). In Figure 2, the number of elements, offset (desired first element, that is), and so on is represented by Metadata Elements.
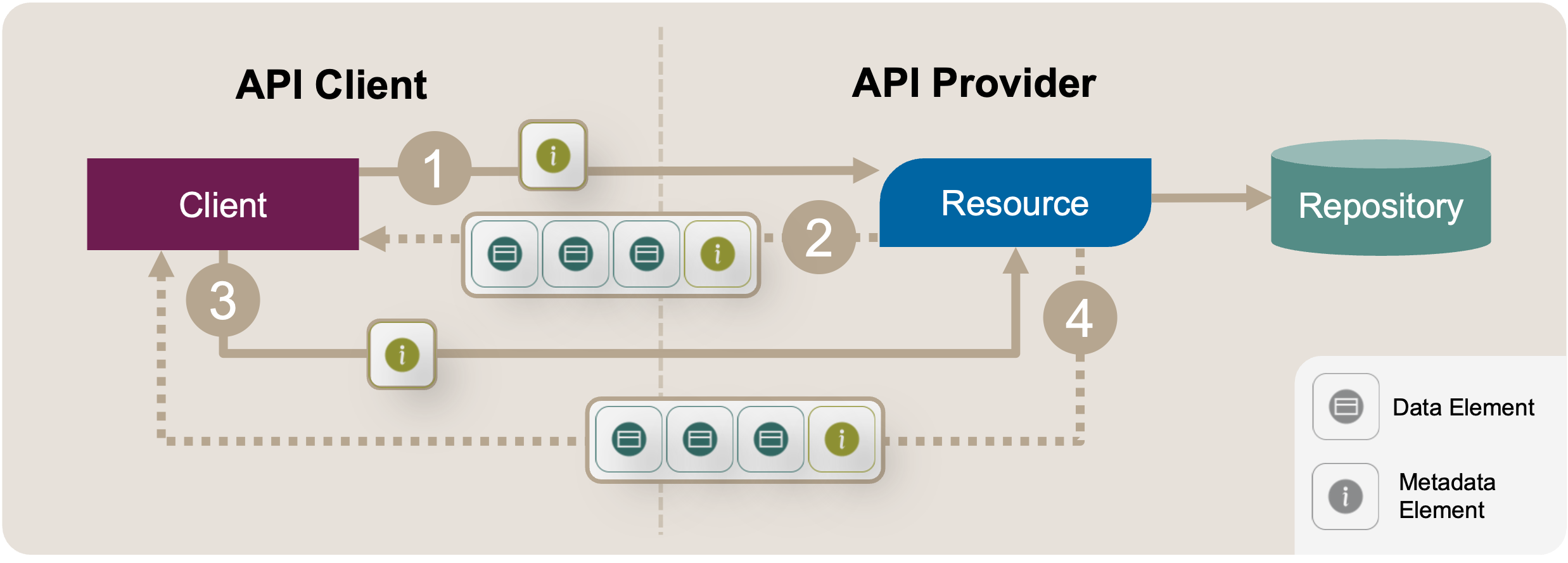
Figure 2: Introduce Pagination: Target Solution Sketch. After the refactoring, the client includes metadata in the request (1) that tells the provider which elements to return. In its response (2), the provider returns the desired elements, along with more metadata (for instance, the total number of elements available). This exchange can then be repeated with follow-up requests (3) and responses (4), where the client can specify the next page (or offset, cursor, depending on the chosen pattern variant).
More but smaller messages are exchanged after the refactoring has been applied.
Example(s)
In this example, we will add Offset-Based Pagination to the Customer Core service of the Lakeside Mutual sample application. The customers endpoint in this service returns a list of customer representations:
$ curl http://localhost/customers
[ {
"customerId" : "bunlo9vk5f",
"firstname" : "Ado",
"lastname" : "Kinnett",
...
}, {
"customerId" : "bd91pwfepl",
"firstname" : "Bel",
"lastname" : "Pifford",
...
} ]
Note that the response is a JSON array of objects. To transmit the Pagination metadata, we first wrap the response in a JSON object (this wrapping is usually done by introducing a DTO that encapsulates the Data Elements), with a customers property to hold the entities:
$ curl http://localhost/customers
{
"customers" : [ {
"customerId" : "bunlo9vk5f",
"firstname" : "Ado",
"lastname" : "Kinnett",
...
}, {
"customerId" : "bd91pwfepl",
"firstname" : "Bel",
"lastname" : "Pifford",
...
} ]
}
Unfortunately, this makes the response backward incompatible. Initially, the array was returned at the top level of the response, but now it is nested inside a customers object. Enabling such future extensibility is why API guidelines (e.g., from Zalando) recommend always returning an object as the top-level data structure in the first place.
With the basic structure in place, we can now add HTTP query parameters (limit, offset) and return the Pagination metadata (limit, offset, size) in our response. Here is a request for the next chunk of elements (including the JSON response to it):
$ curl http://localhost/customers?limit=2&offset=2
{
"limit" : 2,
"offset" : 2,
"size" : 50,
"customers" : [ {
"customerId" : "qpa66qpilt",
"firstname" : "Devlin",
"lastname" : "Daly",
...
}, {
"customerId" : "en2fzxutxm",
"firstname" : "Dietrich",
"lastname" : "Cordes",
...
} ]
}
See the Lakeside Mutual repository for the full Spring Boot implementation, including HATEOAS links and filtering.
Hints and Pitfalls to Avoid
The Data Elements the operation returns typically have an identical structure, as in our example above. Still, Pagination can also be used if the structures of the individual Data Elements differ from each other, as long as there is a sequence of elements that can be split up. If the structure of the response does not comprise a sequence of elements that can be split into pages, the Extract Information Holder refactoring offers an alternative solution to reduce the amount of data transferred.
The API implementation should ensure that the order of elements is consistent when implementing Pagination. For example, the API provider can specify an explicit order by when querying a relational database. Otherwise, clients might receive inconsistent or duplicate results across multiple pages.
Keep in mind that not all API clients are part of end user applications. Backend services can also be API clients that may want to paginate the data they receive.
If the API deployment infrastructure involves load balancers and failover/standby configurations, keep the following in mind:1
- The request for a follow-up page (Step 3 of Figure 2) could go to a different API service provider instance than the first initial request. In that case, that (second) instance would perform another database request to retrieve the second page. However, the data on that second page could have changed in the repository between the two page requests. So this only works for static data that does not change often.
- Data consistency/transaction mechanism: Assuming we are dealing with highly dynamic repository data (e.g., the backend database is constantly changing), we need to either make sure that all page requests reach the same service instance that initially retrieved the data from the database (effectively making the service stateful), or develop a caching mechanism in the repository so that data changes between page requests are not causing data inconsistencies in the client.
- If the service instance fails between the two page requests (assuming the service is now stateful, and we have a routing rule to reach the same instance with each page request), the provider has to notify the client that Pagination has failed entirely, and the client then must retrieve the first page again.
Instead of adding Pagination metadata to the body of the response message, it can be transmitted in HTTP headers, as in the GitHub API. This can be an alternative implementation approach if the body of the response message cannot be adjusted for backward compatibility.
Related Content
The Introduce Data Transfer Object refactoring prepares request and response messages to introduce the Pagination metadata.
“Patterns for API Design” [Zimmermann et al. 2022] describes Pagination and its variants in detail and points at additional information.
References
Fehling, Christoph, Frank Leymann, Ralph Retter, Walter Schupeck, and Peter Arbitter. 2014. Cloud Computing Patterns: Fundamentals to Design, Build, and Manage Cloud Applications. Springer. https://doi.org/10.1007/978-3-7091-1568-8.
Zimmermann, Olaf, Mirko Stocker, Daniel Lübke, Uwe Zdun, and Cesare Pautasso. 2022. Patterns for API Design: Simplifying Integration with Loosely Coupled Message Exchanges. Addison-Wesley Signature Series (Vernon). Addison-Wesley Professional.
-
Thanks to Andrei Furda for suggesting this advice. ↩