Merge Endpoints
Context and Motivation
An API consists of multiple endpoints that expose one or more operations. Two or more of these operations are strongly related to each other. For instance, one can only be executed when the other one has succeeded, or one prepares the data that the other one works with. Because of their mutual dependencies, they have the same reasons to change and usually do so at the same time. This creates an undesired, rather tight coupling between the endpoints.
As an API provider, I want to bring the operations from multiple endpoints together and consolidate them in a single endpoint so that they can be deployed, scaled, and evolved jointly.
Stakeholder Concerns
- #cohesion
- Cohesion refers to “the degree to which the elements inside a module belong together” according to Wikipedia. In the context of this refactoring, the “elements” are the API operations, and the “modules” are the API endpoints. API designers, and software engineers in general, strive for high cohesion, meaning that operations that belong together are offered by the same endpoint. Stevens, Myers, and Constantine [1974] define a scale of cohesiveness that ranges from coincidental, logical, temporal, communicational, sequential to functional cohesiveness. In the highest form, functional cohesiveness, “all of the elements [of a module] are related to the performance of a single function.” The Systems Engineering Body of Knowledge also provides an explanation of this general term.
- #coupling
- According to the Wikipedia entry for this term, coupling is the degree of interdependence between software modules, a measure of how closely connected two modules or API endpoints are. “Strong coupling complicates a system since a module is harder to understand, change, or correct by itself if it is highly interrelated with other modules” [Stevens, Myers, and Constantine 1974]. The pattern summary of Loose Coupling suggests time, platform, reference, and format as key autonomy dimensions. “The Many Facets of Coupling” and other “ramblings” by Gregor Hohpe suggest a “nuanced discussion of coupling”.
- #team-organization
- Both well-established [Conway 1968] and newer literature [Skelton, Pais, and Malan 2019] emphasizes the impact that team structures and organization charts have on software structure and software quality. “Team Topologies” suggests four types of teams: stream-aligned team, platform team, enabling team, and complicated subsystem team. Assuming that these teams provide and consume APIs, changes to the team organization may cause a need to refactor their APIs.
- #understandability (a.k.a. #explainability)
- Fewer endpoints might be easier to understand and maintain—if they are cohesive and do not contain too many operations. The refactorings Move Operation and Rename Operation explain the quality attributes maintainability and understandability further.
Initial Position Sketch
The sketch in Figure 1 shows that the refactoring targets two endpoints and their operations.
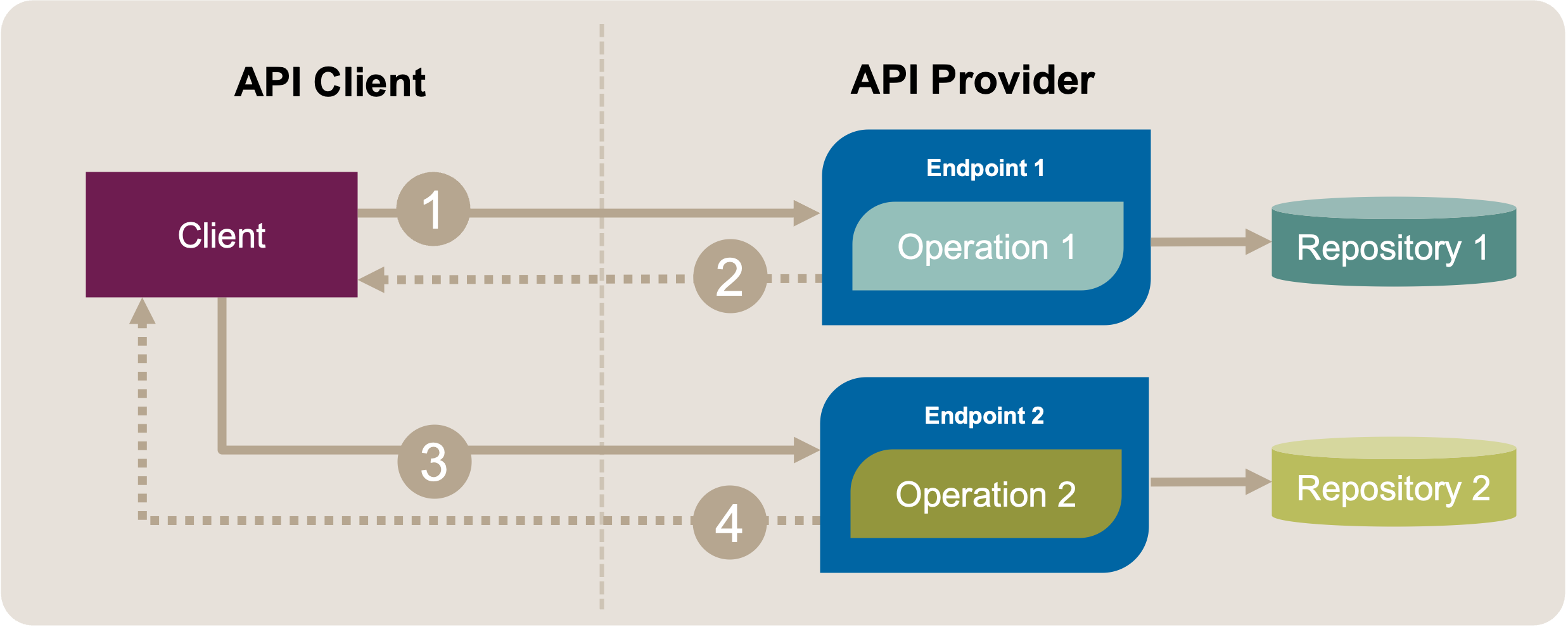
Figure 1: Merge Endpoints: Initial Position Sketch. An API client uses two different operations (message exchanges 1-2 and 3-4) in two API endpoints for its communication with the API.
The client must be aware of and understand both endpoints. According to the context, they are semantically coupled through their operations, so the current API design does not meet the desire for high cohesion.
Design Smells
- API does not get to the POINT
- According to the I in the POINT principles, which stands for Isolation, API operations should be free of unexpected side effects; they should not interfere with calls to other operations in the same or other APIs. The blog post “APIs should get to the POINT” explains the isolation principle (and the other four POINTs) in depth.
- Cloud-native traits violated
- Cloud-Native Applications (CNAs) should be modular with each deployment unit having an adequate size. If two API endpoints are coupled and their operations depend on each other, this rule might be violated. The blog post “What is a Cloud-Native Application Anyway? 10 SUPER-IDEAL Application Properties and 7 Cloud-Native Traits” provides a summary of modularization and other CNA traits.
- Endpoint implementation spaghetti
- The same backend system and/or domain data is processed by multiple endpoints. The endpoints are not self-contained and autonomous, but depend on each other indirectly because they access one or more shared implementation resources (such as another system or a data store). Such “implementation spaghetti” violates several of the defining principles of service-oriented architectures and microservices, for instance independent deployability.
- Extreme decomposition
- A strong desire to decompose an API and its implementation into independently deployable units can be observed, for instance caused by external forces such as the popularity of microservices. This desire has led to an intense decomposition that cannot be justified by requirements and context; numerous endpoints expose narrowly-scoped operations. These operations call each other or have to be orchestrated on the client side.
- Responsibility spread
- Having two highly coupled operations in different modules (here: endpoints) is an indication that the single responsibility principle is violated. As another example, consider a stakeholder group that has to work with multiple endpoints to satisfy its information needs.
- Synonyms for single concept (“aliasitis”)
- Several endpoints have different names but actually expose the same domain concept and are therefore coupled tightly. This smell is related to responsibility spread. Using different names for the same concept to distinguish multiple endpoints could indicate that things are separated that actually belong together. A domain-driven approach such as Context Mapping help decide whether endpoints truly belong to different Bounded Contexts or should be merged.
Instructions
Before applying this refactoring, decide for an evolution strategy for the new merged endpoint that balances the different forces and stakeholder concerns according to the needs of both the provider and the clients of the previously existing endpoints. The following steps can then be used to apply the refactoring:
- Move all operations from the source endpoint to the target endpoint. If an intermediate mapping/configuration from endpoints to classes/methods exists in the Web frameworks that are used to implement the API, adjust both the configuration and the code.1
- Depending on the chosen evolution strategy, implement a new stub to redirect clients to the new endpoint (in HTTP, this can be achieved with URL redirection and status code
301[Fielding and Reschke 2014]). - Delete the now orphaned/empty source endpoint from the code base.
- Update the API test cases. Run them and compare the test results with those of the previous version to ensure that clients are served in the same way as before (both from a functional and from a non-functional point of view).
- Update both API Descriptions (source and target) as well as the related Service Level Agreements. The API description of the target solution must reflect the new design; the one of the source should report the change and, if implemented, the redirect.
- Also update all API directories (i.e., service registries and repositories) and/or portals (i.e., gateways, cluster managers, service meshes) that refer to source and target endpoints.
- Communicate these changes to the affected clients early and consistently.
Target Solution Sketch (Evolution Outline)
After merging the endpoints, the operations are co-located in a single endpoint. Figure 2 visualizes the new endpoint design.
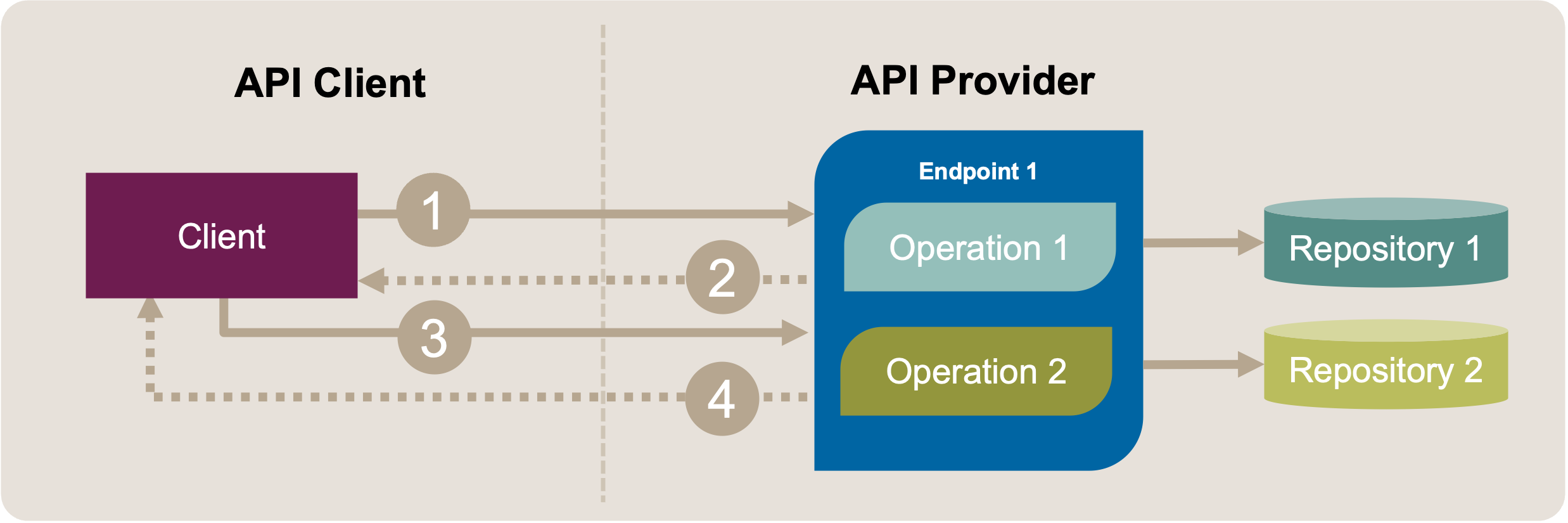
Figure 2: Merge Endpoints: Target Solution Sketch. After the refactoring, the operations (message exchanges 1-2 and 3-4) are co-located in a single API endpoint.
The complete MDSL source and target sketch is here. Its OpenAPI Specification (OAS) version can be found here.
Example(s)
Reverting the target example to the initial/source in Extract Operation qualifies as an example of this refactoring. After Extract Operation has been applied, the publication management example may provide the following command and query endpoints:2
Aggregate PublicationCommandsEndpoint {
Service PublicationManagementCommandFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
}
}
Aggregate PublicationQueriesEndpoint {
Service PublicationManagementQueryFacade {
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String writer);
String renderAsBibtex(@PaperId paperId);
}
}
These two endpoints can be merged into one, leading to the following API design:
Aggregate PublicationEndpoint {
Service PublicationManagementFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String writer);
String renderAsBibtex(@PaperId paperId);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
}
}
Hints and Pitfalls to Avoid
Before and when applying this refactoring, make sure to:
- Watch out for naming conflicts; if a conflict does occur, apply the Rename Operation refactoring before the merge.
- In HTTP resource APIs, make sure that the merge does not cause any conflicts in the operation-to-verb mappings. Each resource, uniquely identified with a URI, is able to support one GET, one POST and one PUT operation (and so forth) only. Update the URI/resource naming scheme if required, for instance via sub-resources.
- Do not take this refactoring to the extreme; creating one endpoint per stakeholder group or per application usually does not make much sense (end user requirements and API-level user/job stories will help to unveil the right API granularity.
The source and the target endpoints may have different security requirements. For instance, some operations may require rather fine-grained, attribute-based authorization while others use role-based authorization (or none). Another case might be one endpoint using basic authentication and API Keys and the other one using OpenID Connect and OAuth. Such situations can either be (viewed as) opportunities to improve the weaker security solution, or as threats because they could cause unexpected/undesired complexity. It is important to identify such mismatches before applying the refactoring and make a conscious architectural decision whether to merge or not.
Related Content
This refactoring undoes Extract Operation. A simpler form of it is Move Operation. Viewed at the code level, Inline Class is a related refactoring that can be used to merge the implementation classes of the endpoints.
There are different reasons why tightly-coupled endpoints exist. If the endpoints are responsible for data retrieval, they might provide access to the same underlying data, but for clients with different information needs. In that case, the Add Wish List or Add Wish Template refactorings might be suited as well.
The general topic of API granularity is discussed in “What is the Right Service Granularity in APIs?”). The Service Cutter tool and method suggest sixteen coupling criteria such as “Semantic Proximity”, “Structural Volatility”, and “Security Contextuality” [Gysel et al. 2016]. These criteria are worth considering when merging endpoints and merging operations.
References
Conway, Melvin E. 1968. “How Do Committees Invent?” Datamation. http://www.melconway.com/research/committees.html.
Fielding, Roy T., and Julian Reschke. 2014. “Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content.” Request for Comments. RFC 7231; RFC Editor. https://doi.org/10.17487/RFC7231.
Gysel, Michael, Lukas Kölbener, Wolfgang Giersche, and Olaf Zimmermann. 2016. “Service Cutter: A Systematic Approach to Service Decomposition.” In Service-Oriented and Cloud Computing - 5th IFIP WG 2.14 European Conference, ESOCC 2016, Vienna, Austria, September 5-7, 2016, Proceedings, edited by Marco Aiello, Einar Broch Johnsen, Schahram Dustdar, and Ilche Georgievski, 9846:185–200. Lecture Notes in Computer Science. Springer. https://link.springer.com/chapter/10.1007/978-3-319-44482-6_12.
Skelton, M., M. Pais, and R. Malan. 2019. Team Topologies: Organizing Business and Technology Teams for Fast Flow. IT Revolution.
Stevens, W. P., G. J. Myers, and L. L. Constantine. 1974. “Structured Design.” IBM Syst. J. 13 (2): 115–39. https://doi.org/10.1147/sj.132.0115.
-
An example of such framework is Play https://www.playframework.com/. Other frameworks work with annotations; Spring and JAX-RS/JAW-WS containers are examples of this distributed configuration approach. ↩
-
The notation in this example is CML, the tactic domain-driven design language supported by Context Mapper https://contextmapper.org/docs/language-reference/. ↩