Extract Operation
also known as: Extract Endpoint
Context and Motivation
One or more API endpoints, for instance, HTTP resources, have been developed, tested, and deployed. One of these endpoints offers multiple operations for clients to call. These operations work with multiple domain concepts. Their functional and technical responsibilities differ regarding stakeholder groups (users, developers, etc.) and their addressed quality concerns. Some operations are process- or activity-oriented, while others offer data storage. At least one operation differs concerning read and/or write access characteristics, access control policies, and data protection requirements. As a consequence, the endpoint serves multiple roles in the API architecture. The operations differ regarding their evolution (e.g., the frequency of changes requiring/leading to new releases).
As the API provider, I want to focus the responsibilities of an endpoint on a single role so that API clients serving a particular stakeholder group understand the API design intuitively, and the release roadmap and scaling of the endpoint can be optimized for each group of stakeholders and clients.To achieve that, I want to remove one or more operations from the existing endpoint and expose them ina new endpoint.
Stakeholder Concerns
- #independent-deployability, #scalability
- Endpoints can be deployed and then scaled separately, which is one of the defining tenets of microservices-based systems [Zimmermann 2017]. The fewer operations an endpoint exposes, the easier it is to optimize the scaling for those operations.
- #reliability and #stability
- Independent endpoints that do not share the same execution context and resources can be deployed independently; operations co-located in a single endpoint, however, share their deployment characteristics. For instance, if a long-running operation causes an API provider-internal error, its sibling operations might suffer from quality-of-service degradations as well. Nygard [2018] uses the term stability: “A robust system keeps processing transactions, even when transient impulses, persistent stresses, or component failures disrupt normal processing.”
- #security
- With multiple operations co-located within a single endpoint, it can be challenging to enforce fine-grained access control policies. Refactoring this endpoint into multiple specialized ones allows for more granular control over access permissions and authorization rules. The security requirements for the data an API endpoint exposes may also differ; hence, separating operations can make it easier to apply data protection measures that ensure confidentiality.
- #single-responsibility-principle
- Architectural principles are affected positively or negatively when APIs are refectored. Here, the Purposeful, style-Oriented, Isolated, channel-Neutral, and T-shaped (POINT) principles for API design apply; extracting an endpoint can improve P, O, and I (but might harm T when looking at a single endpoint and not an entire API).
Initial Position Sketch
The design for this interface refactoring looks as follows (notation: MDSL):
endpoint type SomeEndpoint
exposes
operation operation1
expecting payload "RequestMessage1"
delivering payload "ResponseMessage1"
operation operation2
expecting payload "RequestMessage2"
delivering payload "ResponseMessage2"
See Figure 1 for a graphical representation of this Initial Position Sketch.
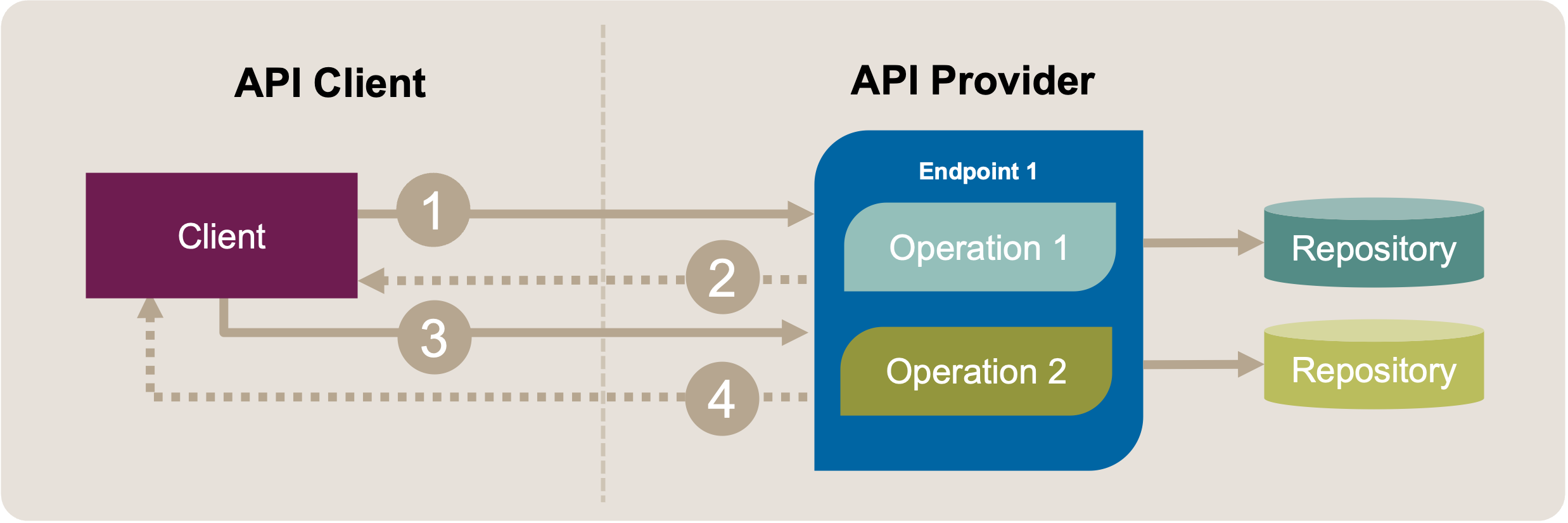
Figure 1: Extract Operation: Initial Position Sketch. A client uses two different operations (message exchanges 1-2 and 3-4) in an API endpoint for its communication with the API.
The refactoring targets are an API endpoint (for instance, an HTTP resource identified with a URI) and one of its operations (for instance, an HTTP verb/method supported by the resource).
Design Smells
- God endpoint
- The endpoint and its operations implementations might have to access many data sources or backend systems to assemble responses to requests. Many such dependencies on external systems and data make the API implementation more complicated to operate and evolve. In object-oriented design, a class or object that controls many other system parts is called a “God Class” [Riel 1996].
- Low cohesion
- The operations in the endpoint deal with multiple, not necessarily related domain concepts. Consequently, the endpoint has more than one reason to change during its evolution. It serves multiple stakeholder groups and/or its implementation is developed and maintained by multiple teams.
- REST principle(s) constraints
- A key design constraint imposed by the REST style used by many HTTP APIs is the “unified interface,” which mandates the use of standard HTTP verbs (POST, GET, PUT, PATCH, DELETE, etc.). These verbs come with certain restrictions; for instance, GET and PUT operations should be idempotent. Sometimes, REST constraints limit extensibility when a resource identified by a single URI runs out of verbs for its operations [Serbout et al. 2022].
- Role and/or responsibility diffusion
- The endpoint is both an Information Holder Resource and a Processing Resource, or an Information Holder Resource exposes different types of data in different operations (for instance, both master data and operational data). The endpoint operations may have rather diverse functional and technical responsibilities (read vs. write, for instance). As a consequence of one or more of these smells, it is hard to explain the endpoint purpose.
- Wrong cuts
- The endpoint might have been designed to serve multiple purposes, and the operations might have been chosen to be co-located in the same endpoint. This design decision might have been made based on the wrong assumptions or requirements, leading to a design that is hard to maintain and evolve.
Instructions
Follow these steps to extract an endpoint:
- Remove the operation from the API Description of the source endpoint.
- Check the general security policies and the client rights management. For example, authorization rules that use endpoint existence and names to determine whether a client application and end-user are permitted to perform an operation might have to be adjusted.
- Refactor at the code level. For instance, create an additional REST controller class when working with Java and HTTP in Spring and move the implementation of the chosen operation.
- Create an API Description for the new endpoint that only exposes the extracted operation.
- Adjust the existing integration tests or add additional ones to verify that the original and new endpoints meet their API Descriptions (both in terms of functional and non-functional characteristics).
- Evaluate whether the roles and responsibilities of the two endpoints are well-separated and that the refactoring resulted in endpoints with higher cohesion.
- Inform all API clients about the change and the version that will introduce it. Provide migration information (or support the transition on a technical level, for instance, with an HTTP redirect [Fielding and Reschke 2014]).
If necessary, repeat these steps with the remaining operations until the roles and responsibilities of the endpoint have been clarified and the smells resolved.
Target Solution Sketch (Evolution Outline)
The following simple and abstract MDSL sketch specifies the result of the refactoring at an abstract level (see Figure 2 for a graphical representation):
endpoint type SomeEndpoint
exposes
operation operation1
expecting payload "RequestMessage1"
delivering payload "ResponseMessage1"
endpoint type ExtractedNewEndpoint
exposes
operation operation2
expecting payload "RequestMessage2"
delivering payload "ResponseMessage2"
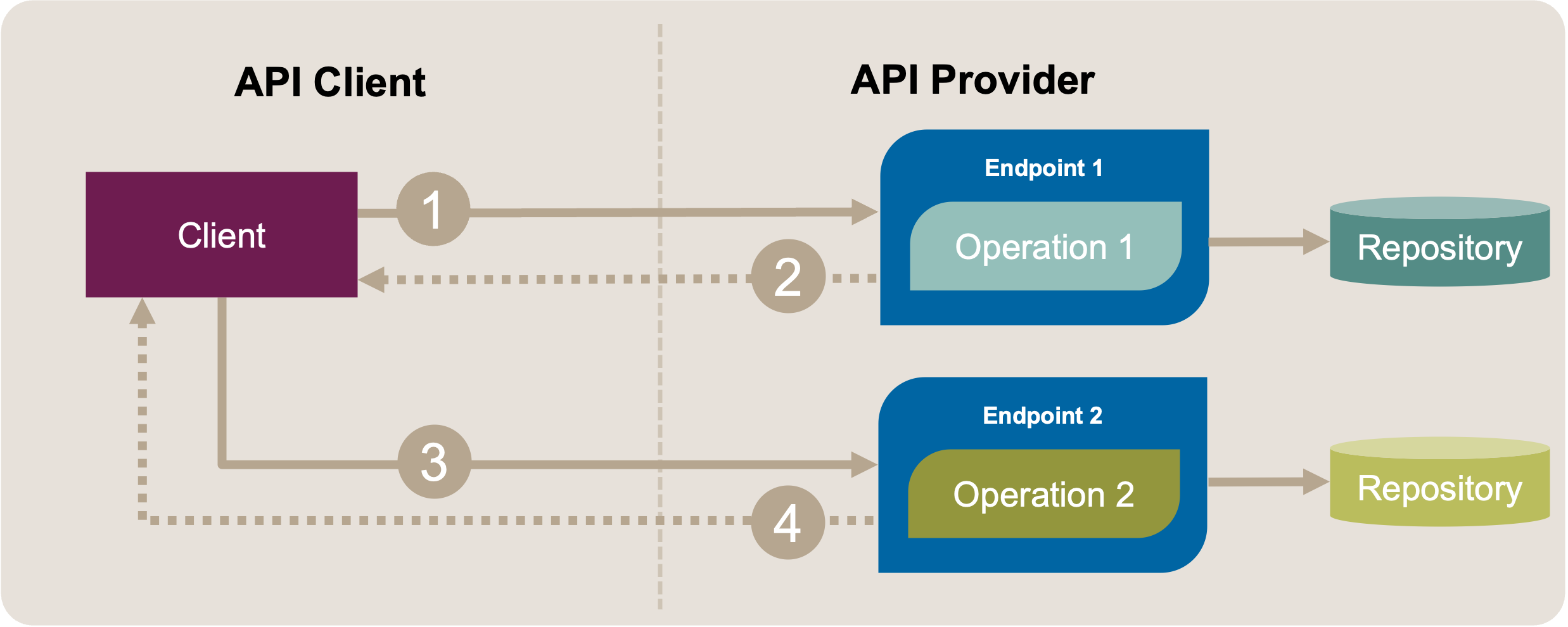
Figure 2: Extract Operation: Target Solution Sketch. The two conversations (message exchanges 1-2 and 3-4) with the API now go to operations residing in two different API endpoints.
Note that this sketch does not show signs of bad smells in terms of semantics or qualities; the following example does.
Example
Sometimes, it makes sense to separate commands from queries (see Segregate Commands from Queries). This refactoring is a particular case of endpoint extraction. Hence, the following example can be seen as an example of both Segregate Commands from Queries and Extract Operation. It starts from a Domain-Driven Design (DDD) featuring a single Aggregate [Evans 2003].
Aggregate PublicationEndpoint {
Service PublicationManagementFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String author);
String exportAsBibtex(@PaperId paperId);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
}
}
The notation in the above snippet is Context Mapper Domain-Specific Language (CML) [Kapferer and Zimmermann 2020]. Context Mapper is a modeling framework for DDD that provides a domain-specific language. DDD can be seen as a form of pattern-oriented, object-oriented analysis and design; “Design Practice Reference” contains introductions to tactic and strategic DDD [Zimmermann and Stocker 2021].
This single publication management Aggregate (and API endpoint) can be split into two, leading to this design:
Aggregate PublicationCommandsEndpoint {
Service PublicationManagementCommandFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
}
}
Aggregate PublicationQueriesEndpoint {
Service PublicationManagementQueryFacade {
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String author);
String exportAsBibtex(@PaperId paperId);
}
}
Note that this design violates principles such as single responsibility, high cohesion, and low coupling because Bibtex-related operations appear in both endpoints. In response, the Move Operation refactoring can be applied on convertToBibtex. A third endpoint that exposes the two BibTeX-related operations can also be introduced.
Hints and Pitfalls to Avoid
When applying this refactoring, API designers have to make sure that:
- Concurrent access to business logic and database from two presentation layers, a.k.a. API endpoints, does not cause issues such as lost updates, phantom reads, deadlocks, and so on [Fowler 2002].
- Performance and independent deployability improve as desired (loose coupling of the original and new endpoint). Extracting an endpoint to focus on a single role redistributes the existing responsibilities and logic across multiple endpoints. This redistribution could affect the performance of the API, especially if there are increased interdependencies or additional network calls are introduced. Proper load testing and performance analysis should be conducted to ensure that the refactored API can handle the expected workload and achieve satisfactory response times.
- Maintainability does not suffer because of design erosion, duplication of Published Language [Evans 2003], and so on. The refactored endpoints may depend on other services or resources within the system. It is essential to carefully manage and coordinate these dependencies to ensure the refactored endpoints can operate independently and reliably.
Related Content
The Extract Information Holder refactoring can be applied in preparation for this refactoring.
When following the Backends For Frontends pattern, it might be helpful to extract an endpoint to serve a particular frontend.
This refactoring is reverted by Merge Endpoints. Segregate Commands from Queries describes endpoint extraction for a particular reason. Move Operation has a similar purpose and nature but does not create a new endpoint.
The Strangler Fig Application pattern describes an approach to migrating a legacy system incrementally by replacing specific functionality with new applications and services instead of replacing it immediately. The Extract Operation refactoring applied to the strangled legacy system can support such an approach. A backend system exposing multiple service endpoints is generally easier to update incrementally (and replace eventually) than a more monolithic one. The blog post “Refactoring Legacy Code with the Strangler Fig Pattern” provides detailed step-by-step explanations.
References
Evans, Eric. 2003. Domain-Driven Design: Tacking Complexity in the Heart of Software. Addison-Wesley.
Fielding, Roy T., and Julian Reschke. 2014. “Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content.” Request for Comments. RFC 7231; RFC Editor. https://doi.org/10.17487/RFC7231.
Fowler, Martin. 2002. Patterns of Enterprise Application Architecture. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc.
Kapferer, Stefan, and Olaf Zimmermann. 2020. “Domain-Driven Service Design.” In Service-Oriented Computing, edited by Schahram Dustdar, 189–208. Springer International Publishing. https://doi.org/10.1007/978-3-030-64846-6_11.
Nygard, Michael T. 2018. Release It!: Design and Deploy Production-Ready Software. Pragmatic Programmers. Pragmatic Bookshelf.
Riel, Arthur J. 1996. Object-Oriented Design Heuristics. Reading, MA: Addison-Wesley.
Serbout, Souhaila, Cesare Pautasso, Uwe Zdun, and Olaf Zimmermann. 2022. “From OpenAPI Fragments to API Pattern Primitives and Design Smells.” In 26th European Conference on Pattern Languages of Programs. EuroPLoP’21. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3489449.3489998.
Zimmermann, Olaf. 2017. “Microservices Tenets.” Comput. Sci. Res. Dev. 32 (3-4): 301–10. https://doi.org/10.1007/S00450-016-0337-0.
Zimmermann, Olaf, and Mirko Stocker. 2021. Design Practice Reference - Guides and Templates to Craft Quality Software in Style. LeanPub. https://leanpub.com/dpr.