Segregate Commands from Queries
also known as: Introduce Command Query Responsibility Segregation (CQRS)
Context and Motivation
An endpoint cohesively bundles all operations dealing with a particular domain concept. Some of these operations modify the application state on the API provider side, while others only retrieve data. Some but not all read operations (following the Retrieval Operation pattern [Zimmermann et al. 2022]) offer declarative query parameters and return rich, multi-valued response structures, causing provider-side workload.
As an API provider, I want to serve queries and process commands separately so that I can optimize the respective read and write model designs independently.
This distinction between commands and queries is known as the Command Query Separation (CQS) principle by Meyer [1997]. CQS states that every method in an object-oriented program should either be a command that performs an action and thus changes state or a query that returns data to the caller, but not both.
Stakeholder Concerns
- #agility and #development-velocity
- Read operations and write operations may evolve at different speeds. For example, data analytics queries may often change, driven by client demand and insights just gained, while commands to modify master data might only change with major releases, if at all.
- #flexibility to change the API vs. #simplicity
- Keeping the read and write operations of an endpoint together is easy to understand and brings functional endpoint cohesion. A separation of these types of operations increases the ability to change them independently from each other; this can then happen more flexibly and more frequently.
- #performance and #scalability
- Computationally expensive workloads such as loading data from data stores, filtering, and formatting it, and high data volumes may make certain operations expensive. Such complex query operations should not slow down cheaper operations exposed by the same endpoint (for example, atomic updates of single attribute values).
- #security, #data-privacy
- Read and write operations might have different protection needs. Few user roles, for instance, are usually authorized to update master data; many or all user roles may read it. If there are two separate endpoints for read and write access, it might be easier to fine-tune the Confidentiality, Integrity, and Availability (CIA) rules and related compliance controls. See the OWASP API Security Top 10 for risks and related advice on API security.
Initial Position Sketch
The operations an API endpoint offers can be sorted into four categories, depending on whether they read/write state. Each target quadrant is represented by a “Pattern for API Design” [Zimmermann et al. 2022], as shown in Figure 1.
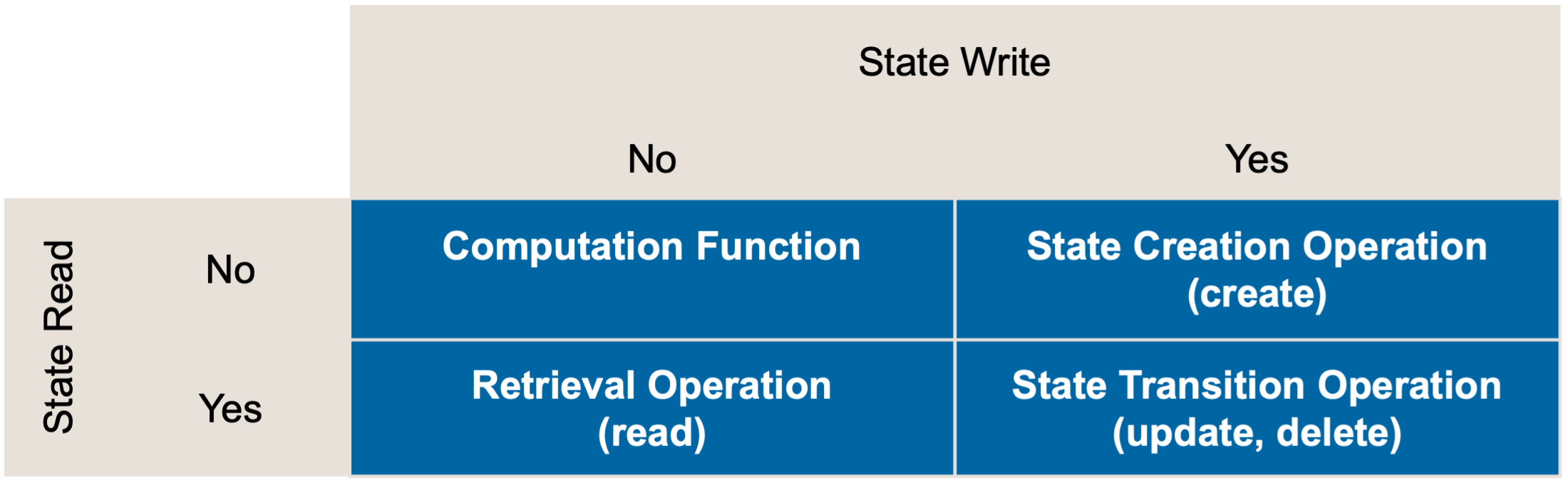
Figure 1: The combination of reading and writing state leads to four different operation responsibilities.
- Computation Functions derive a result solely from the client input, neither reading nor writing server-side state.
- State Creation Operations initialize some new state at the API endpoint (for instance, by creating an implementation resource such as a customer record). A minimal amount of state can be read, for example, to ensure the uniqueness of identifiers.
- Retrieval Operations are read-only queries that clients use to fetch data.
- State Transition Operations update the server-side state, including full or partial replacement and deleting of state.
These operations are often implemented as CRUD (create, read, update, delete) resources, shown in Figure 2.
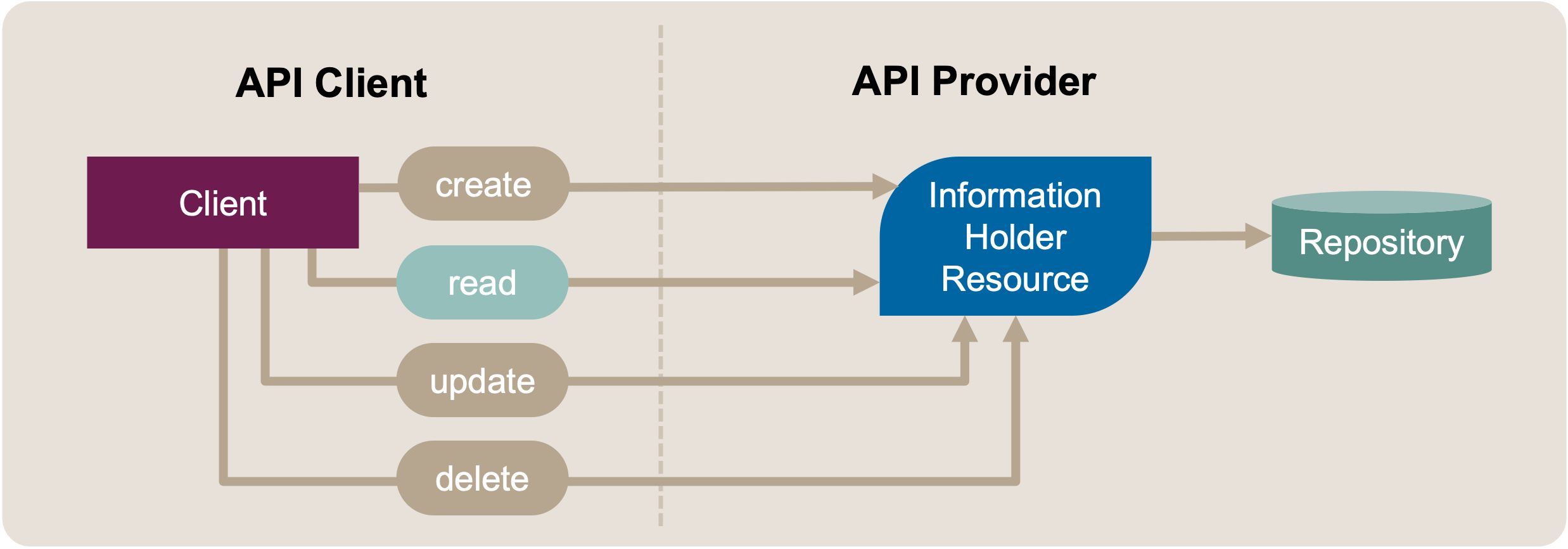
Figure 2: Segregate Commands from Queries: Initial Position Sketch. Commands and Queries in Same Endpoint
The target of the refactoring is an endpoint, such as an Information Holder Resource [Zimmermann et al. 2020] that offers both state-writing and state-reading operations. These operations can be realized by HTTP verbs/methods such as POST, GET, PUT, PATCH, and DELETE, supported by an HTTP resource that a URI identifies.
Design Smells
- Feature/release inertia a.k.a. stale roadmap
- An endpoint provides both read and write operations; there might be many read, but only few write operation calls. These types of operations evolve at different speeds; possibly, different development teams are responsible for them. For instance, new query options in a customer relationship management application may be introduced in every two-week iteration in response to frequently arriving customer inquiries and client insights. In contrast, commands evolve with a frequency imposed by a master data management or Enterprise Resource Planning (ERP) package in the backend. The operations also differ in the amount of design and test work required; write operations change state and, therefore may have nontrivial “given” preconditions and “then” postconditions and require consistency management. The conceptual integrity of the endpoint and all of its read and write operations has to be preserved during each evolution step. As a result, it takes longer than desired to introduce new features, new queries in particular.
- High latency/poor response time
- Poor performance may be caused by too tight operation coupling. Expensive queries slow down the execution of write operations (for instance, operations performing state creation or transition). Transactional isolation is insufficient.
- Too coarse-grained security or data privacy rules
- The security and data protection requirements of commands and queries differ. They are specified on the endpoint rather than the operation level. Hence, generalization has to take place that bears risks such as under-specification and over-engineering.
Instructions
Command Query Responsibility Segregation (CQRS) is an architectural pattern that increases flexibility but adds complexity. It can be introduced in the following steps:
- Classify and group endpoint operations by their purpose and impact on provider-side state: read-only, write-only, read-write, neither-read-nor-write.
- Apply the Extract Operation refactoring to move the read-only operations to a new endpoint, the Read Model API.
- Adjust the API implementation to match the outcome of Steps 1 and 2. Consciously decide for a data store serving both endpoints, the new Read Model API and the already existing endpoint that has become a Write Model API.
- (Optional) Distribute the data store. When distributing data stores, choose suited data replication and consistency management solutions (for example, how current/fresh should the replicated data be?). Include all data stores in the backup and recovery strategy [Pardon, Pautasso, and Zimmermann 2018].
- Test “sunny day scenario” as well as “edge” cases and error situations such as slow and temporarily failing network and replication conflicts.
- Update the API Description, including the technical API contract and supporting documentation.
- Provide teaching material that covers migration from the old domain concept-oriented API to the new command-query API: What has to be changed in the API client? How do the Service Level Agreements change?
The operation responsibility Computation Function neither reads nor writes provider-side application state.1 Such operations may appear in command endpoints as well as query endpoints; they might also go to separate stateless endpoints, yielding a “Command Computation Responsibility Segregation” variant of CQRS.
The messages and operations stay the same when applying this refactoring. However, the resource address might change. An intermediary such as an API Gateway [Richardson 2018], Service Registry, or Version Mediator can be used to preserve backward compatibility by mapping or forwarding messages.
Target Solution Sketch (Evolution Outline)
After applying the refactoring, shown in Figure 3, two distinct endpoints/resources implement the API operations. One is a Processing Resource handling the commands, and the other is an Information Holder Resource handling the queries.
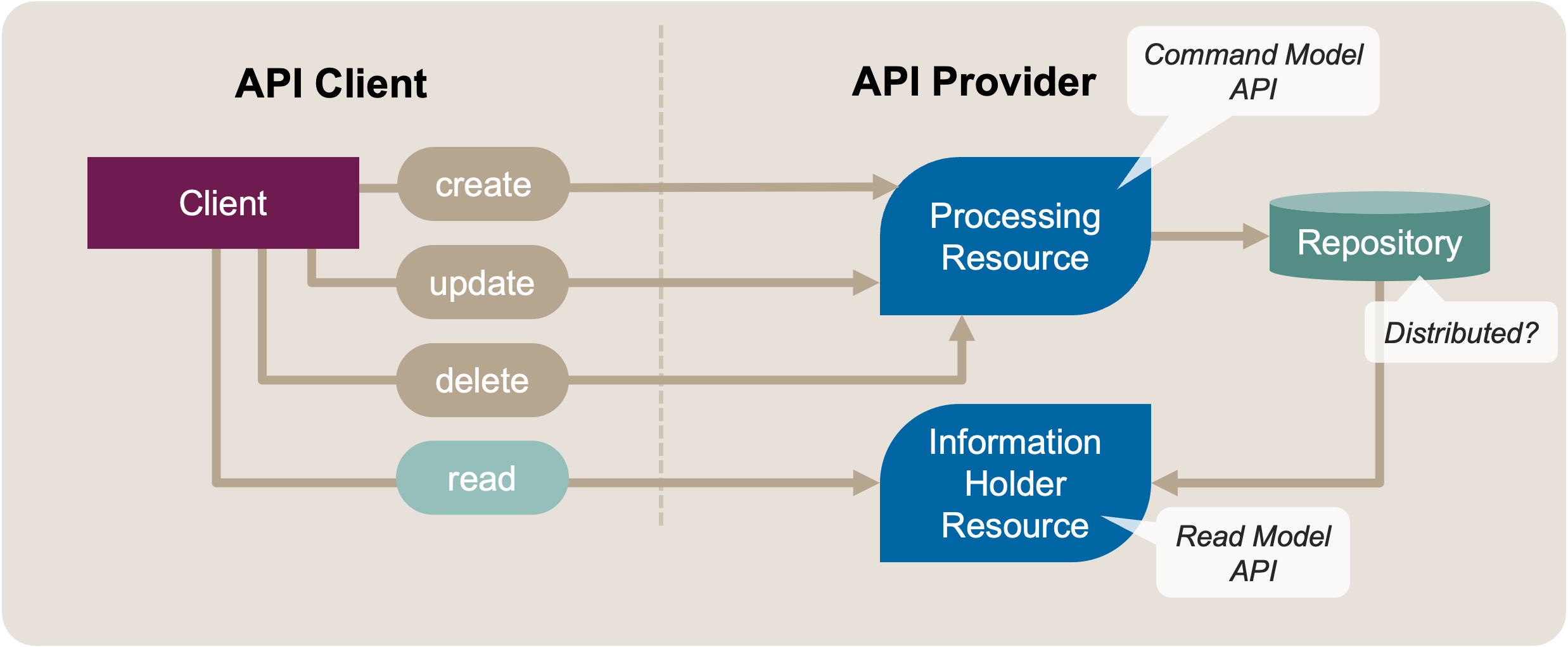
Figure 3: Segregate Commands from Queries: Target Solution Sketch. Commands and Queries in Separate Endpoints
Example(s)
The following example shows an introduction of CQRS (notation: Context Mapper DSL (CML)):
Service PublicationManagementFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String writer);
String renderAsBibtex(@PaperId paperId);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
This single publication management endpoint can be separated into two in this API design:
Service PublicationManagementCommandFacade {
// a state creation/state transition operation:
@PaperId add(@PublicationEntryDTO newEntry);
// computation operations (stateless):
String convertToBibtex(@PublicationEntryDTO entry);
}
Service PublicationManagementQueryFacade {
// retrieval operations:
@PublicationArchive dumpPublicationArchive();
Set<@PublicationEntryDTO>
lookupPublicationsFromAuthor(String writer);
String renderAsBibtex(@PaperId paperId);
}
This API design achieves command-query segregation at the expense of distributing the two operations related to BibTeX to two different endpoints. Consequently, the two endpoints are coupled from a domain design standpoint (to some extent).
Hints and Pitfalls to Avoid
When deciding to separate commands from queries by introducing the CQRS pattern:
- Replicate data as needed. Decide between strict and eventual consistency consciously. Consistency, availability, and partition tolerance (CAP) are desirable properties of distributed systems. The CAP theorem “asserts that any networked shared-data system can have only two of three desirable properties”. See Brewer [2012] for a discussion of the theorem and its implications on distributed system design.
- Be aware of the implications of the Backup Availability Consistency (BAC) theorem [Pardon, Pautasso, and Zimmermann 2018]. The BAC theorem states that it is not possible to back up and restore across services consistently without degrading availability.
- Acknowledge that read models and event messages sent as Data Transfer Objects (DTOs) over APIs increase the data coupling between clients and providers. If multiple clients use the same DTOs, they might indirectly also be coupled consequently.2
- Consider asynchronous, queue-based messaging to update the read model after a change to the write/command model caused by an API command or a backend activity. This integration style supports throttling and is able to guarantee message delivery (depending on the quality-of-service properties chosen for a particular queue).
- Consider applying Event Sourcing as one of several options when segregating commands from queries. An event source stores a series of state changes in chronological order but does not store the resulting final/current state. In such designs, it often makes sense to take snapshots of the current state periodically or upon client request; such snapshots can then be stored separately from the events and provided to clients via additional calls to API operations.
Related Content
This refactoring refines Extract Operation in the context of CQRS; hence, Merge Endpoints reverts it. It can be seen as a special type of frontend distribution and backend split; three of our catalog entries (Distribute Application Frontend, Split Application Backend Logic, and Split Application Backend Persistence) describe related architectural refactorings. Introduce Pagination and Add Wish List might be alternative options to improve query performance. The Introduce Data Transfer Object refactoring explains DTO usage.
Information Holder Resources of various types are related patterns that may benefit from command-query segregation. In “Patterns for API Design” [Zimmermann et al. 2022], queries are represented as Retrieval Operations; commands are State Creation Operations or State Transition Operations.
Michael Ploed provides a comprehensive introduction to CQRS and event sourcing on slideshare. A presentation video by Michael Ploed is available as well. Also see an online article by Udi Dahan for examples and a discussion of pros and cons. The Context Mapper website provides a tutorial, “Event Sourcing and CQRS Modeling in Context Mapper.”. Chapter 24 in “Patterns, Principles, and Practices of Domain-Driven Design” is about CQRS [Millett and Tune 20915].
References
Brewer, Eric. 2012. “CAP Twelve Years Later: How the “Rules” Have Changed.” Computer 45 (2): 23–29. https://doi.org/10.1109/MC.2012.37.
Evans, Eric. 2003. Domain-Driven Design: Tacking Complexity in the Heart of Software. Addison-Wesley.
Meyer, Bertrand. 1997. Object-Oriented Software Construction (2nd Ed.). USA: Prentice-Hall, Inc.
Millett, Scott, and Nick Tune. 20915. Patterns, Principles, and Practices of Domain-Driven Design. Wrox.
Pardon, Guy, Cesare Pautasso, and Olaf Zimmermann. 2018. “Consistent Disaster Recovery for Microservices: The BAC Theorem.” IEEE Cloud Computing 5 (1): 49–59. https://doi.org/10.1109/MCC.2018.011791714.
Richardson, Chris. 2018. Microservices Patterns. Manning.
Zimmermann, Olaf, Daniel Lübke, Uwe Zdun, Cesare Pautasso, and Mirko Stocker. 2020. “Interface Responsibility Patterns: Processing Resources and Operation Responsibilities.” In Proc. Of the European Conference on Pattern Languages of Programs. EuroPLoP ’20. Online.
Zimmermann, Olaf, Mirko Stocker, Daniel Lübke, Uwe Zdun, and Cesare Pautasso. 2022. Patterns for API Design: Simplifying Integration with Loosely Coupled Message Exchanges. Addison-Wesley Signature Series (Vernon). Addison-Wesley Professional.
-
unlike State Creation Operation, Retrieval Operation, and State Transition Operation ↩
-
This cannot be avoided entirely in any Published Language [Evans 2003] in an API; the coupling still exists but becomes less obvious when commands and queries are separated (as they still work on the same domain concepts). If the two endpoints evolve autonomously (independently of each other, that is), the models will eventually deviate further and further (which to some extent is desired). Over time, this may cause technical debt and hidden dependencies that counter the original motivation of the pattern and the refactoring. If this happens, the inverse Merge Endpoints refactoring may be applied. ↩